
Publication
Recommandations sur les usages du webscraping au sein d'INRAE
En février 2025, l’INRAE, accompagné par inno³, a publié des « Recommandations sur les usages du webscraping au sein d’INRAE » avec pour objectif d’accompagner les professionnel.le.s de la recherche dans l’usage de cette méthodologie facilitant la récolte de données.
Le webscraping est défini comme un moyen d’obtenir des données non disponibles autrement (non disponibles via une API ou dans des bases de données en open data) en réalisant une extraction automatique de données sur un site web. Cette méthodologie permet aux professionnel.le.s de la recherche de gagner du temps en évitant une extraction manuelle, en ciblant précisément les informations à récolter tout en les organisant dans des bases de données. Au travers d’un script ou d’outils dédiés, la récolte de données se fait automatiquement et peut être relancée afin de garder les bases de données à jour.
Notons que le webscraping est à différencier du crawling et du Text and Data Mining (TDM) qui sont des méthodologies permettant respectivement de parcourir le web en suivant des liens (ex. indexation) et la fouille de données textuelles pour en extraire de l’information.
Cependant, ces pratiques soulèvent des questions juridiques, techniques et éthiques. Pour lister ces questions et proposer des pistes de solutions, l’INRAE a mandaté inno³ pour animer une étude de terrain auprès des professionnel.le.s de la recherche de l’INRAE et mieux comprendre leurs pratiques et usages du webscraping.
Contexte de l’étude
Actuellement, l’extraction de données issues de site web peut être réglementé par le Règlement Général de Protection des Données (RPGD) ou par des réglementations sur le droit d’auteur (en France, le Code de la propriété intellectuelle, en Europe, la Directive européenne 2019/790 sur le droit d’auteur). Cependant, un flou juridique demeure laissant les professionnel.le.s de la recherche dans l’interrogation pour savoir si le webscraping peut être utilisée ou non dans le cadre de leur projet de recherche. Dans ce cadre, il est complexe de savoir si les responsables de projets sont dans la légalité, peuvent publier leurs articles, mettre en ligne leurs jeux de données et plus généralement poursuivre leur étude.
Pour étudier ces problématiques, inno³ a mené une série d’entretiens semi-directifs avec des équipes de recherche de l’INRAE. Ainsi, ces entretiens ont aussi permis de comprendre les pratiques, les usages et les points de blocage relatifs à l’utilisation du webscraping. En s’appuyant sur ces expériences, des premiers points de friction ont été repérés :
- un manque de connaissance juridique (ex. est-ce que j’ai le droit de scraper un site web, dois-je le prévenir un amont, quid de la législation européenne ou encore internationale, etc.),
- un manque de compétences techniques ou d’outils adaptés (ex. comment paramétrer le script, quel temps de latence entre deux requêtes, etc.),
- une assurance de la qualité, la fiabilité et la complétude des données récoltées afin d’assurer la reproductibilité des études.
Afin de répondre à ces points de frictions, ou au moins amener des pistes de réponse, l’INRAE a décidé de publier un document de recommandations, conçu avec l’appui d’inno³.
Structuration de l’étude
Afin d’accompagner au mieux les personnes souhaitant employer ces méthodes, l’étude a été pensée avec une approche didactique en proposant des outils tels que des checklists, des liens utiles, des listes de bonnes pratiques ou encore des personnes à contacter en cas de questions sur des points précis.
De plus, pour faciliter la lecture de l’ensemble de ces outils, l’étude est structurée en suivant les étapes du cycle de vie des données scrapées inspiré par le cycle de vie des données proposées par DoRANum.
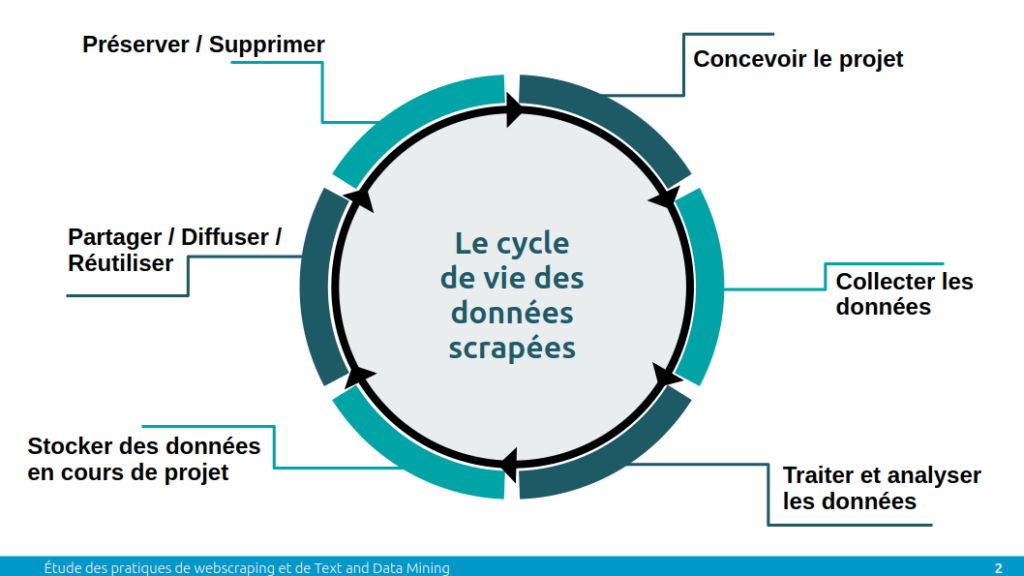
- Concevoir le projet
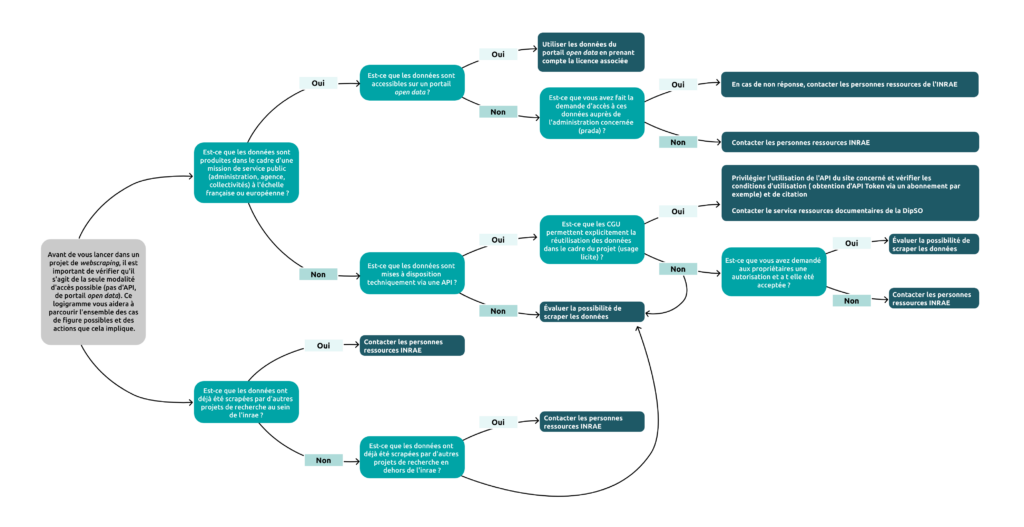
- Logigramme « Accès aux données » pour identifier où trouver les données avant d’utiliser la méthodologie de webscraping (ex. jeu de données en libre accès, API déjà existante),
- Checklist « Conception du projet » identifiant les étapes majeures à valider avant de lancer un projet (ex. avoir un plan de gestion de données).
- Collecter les données
- Tableau « Caractérisation des données » afin de caractériser les données en lien avec le plan de gestion de données,
- Checklists « Collecte des données » et « Préparation de la collecte des données » identifiant les étapes majeures à valider avant de lancer la collecte des données.
- Traiter et analyser les données
- Informations sur les données sensibles.
- Stocker des données en cours de projet
- Checklist « Stockage et sécurité des données scrapées » identifiant les étapes majeures permettant de garantir un stockage et une sécurité suffisant des données au cours du projet.
- Partager / Diffuser / Réutiliser
- Logigramme « Partage des données »,
- La Science Ouverte dans le contexte du webscraping,
- Quelques idées reçues (cf. illustration « Capture d’écran du rapport présentant les idées reçues »),
- Checklist « Partage et réutilisation des données et conditions associées » reprenant les étapes majeures avant de partager / diffuser les résultats de la recherche.
- Gradient de partages possibles des données.

- Préserver / Supprimer
- Checklist « Stockage à long terme des données scrapées » permettant de suivre les principales étapes pour stocker les données récoltées sur le long terme.
L’étude réalisée et l’ensemble des schémas sont disponibles dans le document disponible sur HAL sous licence CC-by 4.0.



Citer la publication
Hadi Quesneville, Odile Hologne, Muriel Lightbourne, Cécile Janet, Timothée Gardin, et al.. Recommandations sur les usages du webscraping au sein d’INRAE. 2024, 19 p. ⟨10.17180/vka1-ng75⟩. ⟨hal-04803028⟩
Ressources associées
Licence
Organisation(s) impliquée(s)
INRAE