
Publication
Rapport d'étude : valorisation et réutilisation de données pour la création de modèles d'intelligence artificielle
En 2024, inno³ et Open Knowledge Foundation ont accompagné la juriste et chercheuse en droit Ramya Chandrasekhar (CIS-CNRS) dans le cadre de son projet de recherche dédié à la valorisation et à la réutilisation de données pour la création de modèles d’Intelligence Artificielle (IA). Un rapport publié en début d’année 2025 apporte quelques conclusions éclairantes sur les controverses actuelles concernant l’utilisation de données du web pour entrainer des modèles IA et la place de l’ouverture dans ces débats.
Le projet de recherche ODECO (Open Data ECOsystem), débuté en octobre 2021 pour 4 ans, avait pour objectif de questionner l’environnement des données ouvertes à l’échelle européenne. Dans ce cadre, Ramya Chandrasekhar a été impliquée dans l’ »ESR3 – Value assessment and (re-)distribution in sustainable ODECO » qui se concentre sur la valorisation et la réutilisation de données ouvertes pour créer de nouveaux modèles. Dans le cadre d’une étude de cas sur les données d’entrainement des modèles d’Intelligence Artificielle, elle a travaillé conjointement avec inno³ pour mieux comprendre l’usage de données issues du web dans ces modèles (foundation model).
L’objectif a été pour Ramya, en s’appuyant sur l’expertise et les réseaux d’inno³ Open Source/open data, d’analyser d’une part les différents points d’achoppement de l’usage de ces données au sein de ces modèles et d’autre part, d’étudier des solutions /initiatives actuelles combattant notamment un extractivisme de données non respectueux des personnes et des cultures.
Présentation du projet
Le fonctionnement des IA, notamment les IA génératives et les modèles de LLM (Large Language Model), reposent avant tout sur des données d’entrainement présentes sur le web ouvert (open web dans le rapport). Elles peuvent être de différentes natures : données ouvertes accessibles sous une licence ouverte ou dans le domaine public, données publiques et données disponibles sous certaines conditions.
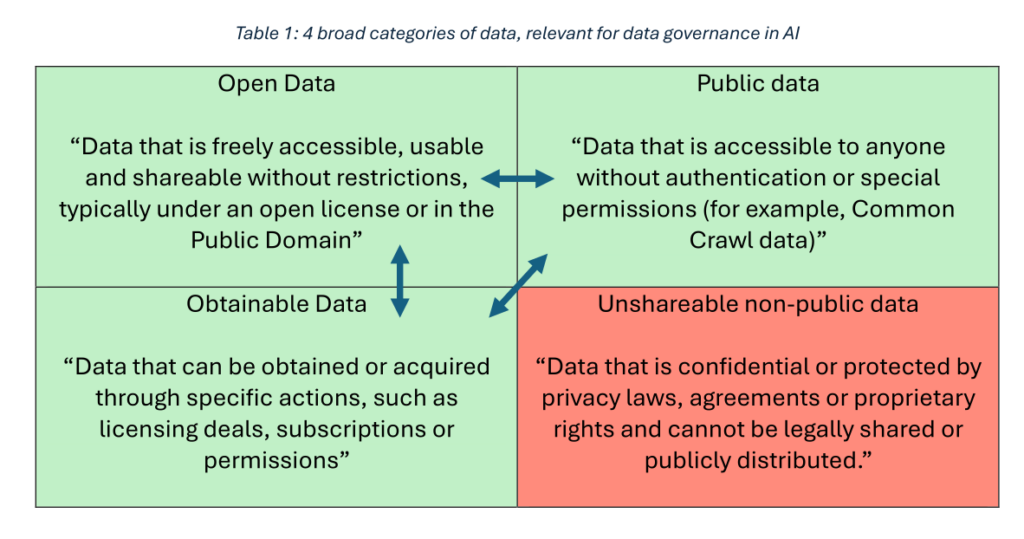
This report focuses on “foundation models” – i.e. AI models that rely on large amounts of training data, as well as large quantities of computational resources for processing this training data.
Définition proposée dans le rapport.
Lors de l’utilisation de ces données pour l’entrainement de modèle d’IA, plusieurs difficultés se rencontrent.
Premièrement, il est difficile d’avoir un suivi du flux des données employées. Comment sont-elles réutilisées, où et pourquoi ? Il est, par exemple, complexe d’identifier l’origine des données une fois celles-ci assemblées pour développer un modèle d’IA.
Ensuite, comme spécifié dans le rapport, d’un point de vue juridique et politique, dans le contexte de l’IA, les flux de données sont considérés comme « traçables, stables et contenus », alors qu’en réalité, la réutilisation des données est un « phénomène intrinsèquement enchevêtré ».
Méthodologie et phases de recherche
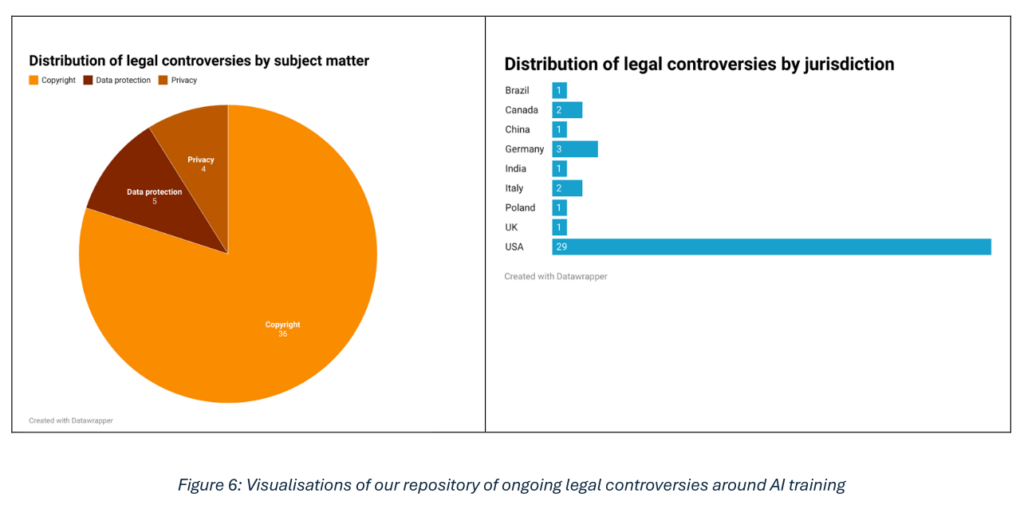
Afin d’étudier les problématiques précédemment posées, la première étape de recherche a été d’analyser un ensemble de controverses juridiques en lien avec le droit d’auteur et la protection des données employées pour l’entrainement de modèles IA.
Ramya a également animé une série d’entretiens semi-directifs avec des personnes utilisant ou créant des modèles d’IA et des responsables politiques européens et nord-américains. Afin de compléter ces entretiens, un atelier conviait des utilisateurs et des utilisatrices de modèles d’IA, des chercheurs et chercheuses et des décideurs de différentes origines (Europe, USA, UK, Afrique Subsaharienne).
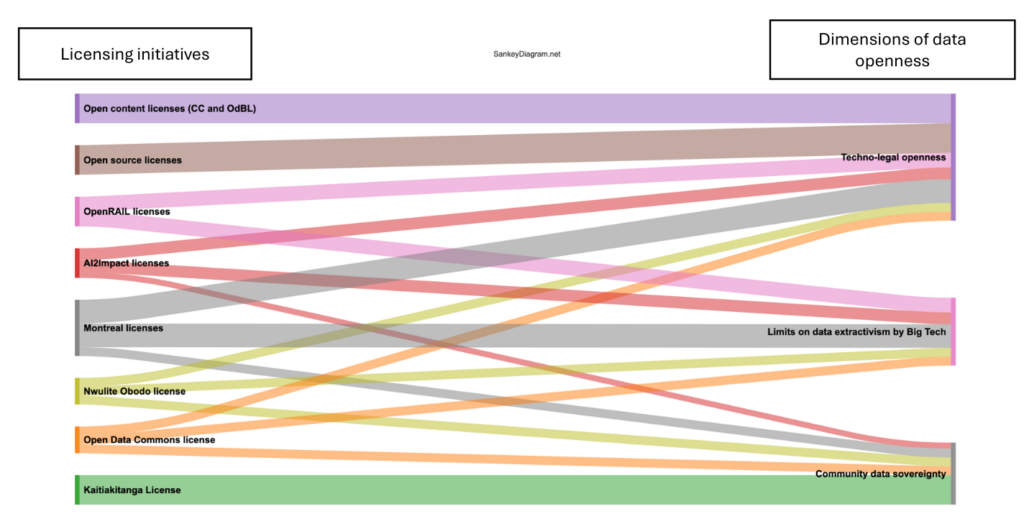
En parallèle, un ensemble de licences ouvertes et permissives ainsi que des licences alternatives abordant les problématiques liées à l’IA, a été analysé pour comprendre leur rapport à l’ouverture des données. Sur la base de ces recherches qualitatives, un répertoire de controverses a été créé en prenant des cas internationaux : États-Unis, Europe, Royaume-Unis, Inde, Brésil, Canada et Chine.
Principaux résultats et contenus produits
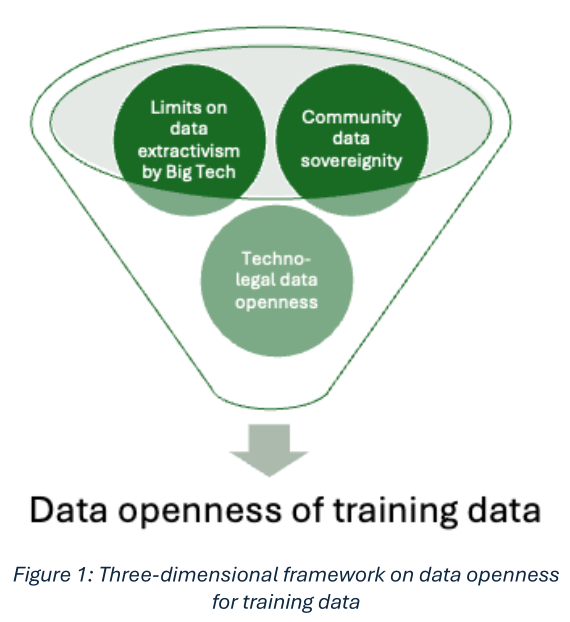
Dans le rapport, plusieurs tensions entre les modélisations de flux de données et le développement de modèles d’IA sont soulignées. On peut mettre en avant quelques éléments clefs du rapport :
- La construction d’un cadre tridimensionnel pour comprendre les enjeux d’ouverture dans le contexte de données d’entrainement des modèles d’IA,
- Une liste de 41 controverses juridiques, en cours concernant les droits d’auteurs et la protection des données d’entrainement des modèles d’IA,
- Une analyse critique des licences Open Source, des licences permissives et de licences alternatives dans le contexte de l’entrainement de données pour des modèles d’IA.
Ce rapport est disponible sur l’archive nationale HAL (en anglais) sous licence CC-by-SA 4.0 : https://hal.science/hal-05009616
Pour citer l’article : Ramya Chandrasekhar. Legal frictions for data openness: Reflections from a case-study on re-use of the open web for AI training. Centre Internet et Société – CNRS; Inno3; Open Knowledge Foundation. 2025, pp.75. ⟨hal-05009616⟩


Citer le rapport
Ramya Chandrasekhar. Legal frictions for data openness: Reflections from a case-study on re-use of the open web for AI training. Centre Internet et Société – CNRS; Inno3; Open Knowledge Foundation. 2025, pp.75. ⟨hal-05009616⟩