
Science ouverte : comment identifier des axes d’explorations dans un contexte transdisciplinaire
Par Olga Kokshagina, STIM, & Yohann Sitruk, Mines ParisTech
Article publié originellement dans Paris Innovation Review, le 13 octobre 2017 et partagé sous licence CC-BY-ND.
STIM est partenaire du programme Epidemium et l’accompagne notamment dans sa conception grâce à son expertise sur le management de l’innovation et sur la méthodologie C-K.
Epidemium est un projet de « science ouverte » qui vise à utiliser les Big Bata pour comprendre le cancer, en mobilisant une grande variété d’acteurs et de spécialistes. Plus facile à dire qu’à faire. Car, dans sur un sujet aussi pointu, comment utiliser efficacement les logiques de l’open source et de l’innovation ouverte pour aider les scientifiques à développer des solutions originales et faire progresser les connaissances? Les méthodes émergentes d’analyse des données peuvent permettre de mieux comprendre des domaines complexes comme la médecine ou les sciences de la vie. Mais cela exige de formuler des problèmes compréhensibles à la fois pour les médecins, les patients et les scientifiques. La méthode C-K (Concept-Knowledge) offre une solution.
Les publications en libre accès, les technologies de la communication et les plateformes numériques contribuent à élargir l’accès au savoir et permettent d’ouvrir la science à des tiers possédant une expertise spécifique, qui peuvent contribuer à la résolution de questions importantes.
L’accès à l’information, traditionnellement considéré comme un élément stratégique dans toute organisation de recherche scientifique, n’est plus limité à quelques acteurs capables d’investir dans des programmes de R-D longs et coûteux. Il est maintenant accessible à presque tous ceux qui souhaitent apprendre, expérimenter et éventuellement apporter une contribution scientifique. La publicité croissante des processus scientifiques stimule l’émergence de communautés autour de certains projets. Ces communautés ouvertes sont de plus en plus mobilisées pour résoudre des problèmes spécifiques, et parfois pour aboutir à de véritables découvertes scientifiques.
Comme l’ont souligné Sauermann et Franzoni (2015), une part croissante de la recherche scientifique se fait de manière ouverte. On peut trouver des exemples dans différents domaines et disciplines.
Par exemple, le projet Polymath lancé en 2009 par Tim Gower visait à faire collaborer des mathématiciens pour résoudre des problèmes difficiles ; tout l’enjeu était de coordonner de nombreux spécialistes et leur permettre de communiquer les uns avec les autres sur la recherche de la meilleure voie à la solution. Polymath a donné lieu à plus de 12 défis. Le projet a prouvé qu’il était possible de développer des modes de coopération permettant de résoudre des problèmes mathématiques difficiles.
Autre exemple, un projet conjoint entre Harvard, TopCoder, le Broad Institute et le Crowd Innovation Lab a été lancé pour organiser une série de défis sur le développement d’algorithmes pour un alignement plus rapide des séquences d’ADN et pour améliorer l’analyse des données d’expression génétique.
Les initiatives ouvertes peuvent ainsi contribuer à résoudre des problèmes extrêmement complexes. Ces projets font souvent référence à au « crowdsourcing » et à la « science ouverte » (open science). Ils se caractérisent par une participation ouverte et le partage des données et des techniques de résolution de problèmes avec les participants. Les promoteurs de la science ouverte mettent souvent en avant la possibilité d’apprendre, de collaborer avec les autres et de tester de nouvelles théories.
La science ouverte dans la recherche sur le cancer
Ces dernières années, les sciences de la vie et la médecine ont connu des changements majeurs avec l’apparition de nouvelles sources massives d’information telles que l’identité génomique ou l’environnement global des patients. Parallèlement, de nouvelles formes de traitement sont désormais disponibles, telles que les biothérapies, qui prennent en compte des maladies comme le cancer dans leur environnement global, ou les traitements personnalisés basés sur l’information du génome du patient. De nombreux domaines, comme l’épidémiologie, connaissent des transformations majeures qui requièrent de nouvelles méthodes d’analyse des données. Ces disciplines utilisent maintenant des cadres de collaboration ouverts pour explorer de nouvelles façons de traiter ces sources massives de données.
Epidemium, une initiative de collaboration visant à explorer de nouvelles voies pour la recherche sur le cancer, a été lancée en 2016. Epidemium est un programme scientifique ouvert, inclusif et communautaire, offert conjointement par une société pharmaceutique, Roche, et un laboratoire ouvert et communautaire, La Paillasse. Le programme organise des data challenges, « Challenge4Cancer », pour aborder l’épidémiologie du cancer dans un cadre scientifique ouvert en mobilisant les Big Data.
Lancé en 2016, le premier challenge a été… un défi : 678 personnes ont participé à la création d’une vaste communauté d’experts qui ont apporté diverses compétences en analyse de données, statistiques, visualisation, exploration de données, oncologie, épidémiologie. Au total, 15 projets différents ont été développés en six mois. Ces projets ont fait l’objet d’une évaluation par les comités scientifiques et éthiques afin de contrôler la validité scientifique des résultats, l’originalité, l’aspect collaboratif, l’impact et les perspectives sur les patients des approches proposées, tout en vérifiant vérifier que les explorations étaient éthiquement correctes.
Dans une perspective de partage des connaissances, les participants de Challenge4Cancer devaient documenter leurs progrès et résultats sur une page wiki accessible à tous. Cette transparence a permis de poursuivre la discussion durant le défi et de créer une communauté dynamique.
Malgré ces réalisations, certaines difficultés liées à la nouveauté, à la validité des résultats et à l’identification d’orientations de recherche prometteuses ont été soulignées. L’un des points critiques était l’identification des questions et des défis de la recherche.
Les spécialistes du crowdsourcing et de l’innovation ouverte savent bien que la formulation des problèmes est l’un des facteurs clés pour assurer des résultats positifs et attirer les bons participants. Les problèmes devraient être suffisamment précis, sans être trop étroits, notent Felin et Zenger (2014). C’est tout spécialement vrai pour les défis transdisciplinaires en open source. Comme l’a souligné Godemann (2008), le croisement de diverses formes de connaissances de différentes disciplines a des effets positifs pour la résolution de problèmes, mais il soulève des difficultés dans l’échange et l’intégration des connaissances. Compte tenu de la courte durée du défi et de la diversité des participants, l’appropriation des domaines de recherche devrait être mieux gérée par la communauté. Les questions de recherche devraient être compréhensibles pour les différentes communautés mobilisées : médecins, patients, spécialistes du traitement des données. Ils doivent également être originaux et ambitieux, afin d’attirer des participants hautement qualifiés.
Compte tenu de l’importance de la conception des orientations de recherche, Epidemium a décidé en 2017 de lancer une exploration préliminaire pour mieux comprendre les enjeux et identifier les questions de recherche les plus pertinentes.
Définir de nouvelles orientations de recherche: l’apport de la méthode C-K
Résoudre des questions à l’aide de nouvelles approches est passionnant. Mais il est crucial de poser les bonnes questions. Quelle est la lacune de connaissances à analyser ? Comment identifier dans la recherche sur le cancer les lacunes que l’usage des Big Data contribuer à combler ? Comment s’assurer que les données pertinentes sont collectées ?
Pour définir des questions de recherche, on analyse habituellement les lacunes existantes dans la connaissance scientifique et on tente de formuler des questions suffisamment nouvelles. Dans le cas d’Epidemium, l’état de l’art est assez vaste, ne serait-ce que parce qu’il comprend à la fois des disciplines liées au cancer et à l’analyse de données. Il aurait été trop coûteux et trop long de procéder à une analyse documentaire traditionnelle. De plus, puisque le défi vise à développer des connexions entièrement nouvelles entre les différentes disciplines, les progrès des connaissances devraient être présentés d’une manière concise et suffisamment simple pour permettre aux non-experts de comprendre rapidement ce qui se passe.
Afin d’explorer de façon systématique les possibilités liées à l’analyse des données et à la recherche sur le cancer, d’identifier le cadre des approches actuelles et de générer un ensemble de concepts novateurs, on a utilisé un cadre conceptuel fondé sur une nouvelle théorie de la conception. Ce cadre était fondé sur un outil dérivé de Concept Knowledge (C-K), une théorie de la conception innovante.
Voir La théorie C-K, ou comment modéliser la créativité, par Pascal Le Masson
Le cadre général de la design theory a été choisi parce qu’il permet une expansion des connaissances qui va au-delà des simples stratégies combinatoires et considère les transformations dynamiques, les adaptations, les hybridations, la découverte, l’invention et le renouvèlement de la découverte d’objets. Le cadre conceptuel de C-K permet de comprendre la nouveauté puisqu’il permet non seulement de distinguer l’état de la technique (connaissances disponibles, le « k » de knowledge) et la phase d’exploration (développement du concept), mais aussi de définir comment utiliser les connaissances existantes pour structurer l’inconnu.
La théorie C-K est basée sur deux espaces interdépendants. L’espace Concepts a une structure arborescente. Cet arborescence souligne les trajectoires de conception de chaque idée et met l’accent sur sa relation avec les autres domaines. L’espace K, celui de la connaissance, est représenté par des bases de données de connaissances où l’on peut mettre l’accent sur différents types de connaissances (avec mention de leur robustesse et de leur maturité).
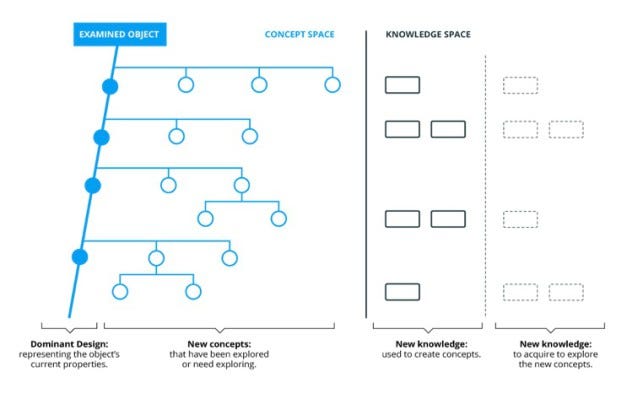
Cartographier les orientations potentielles de la recherche sur le cancer à l’aide des Big Data
En plus des ateliers auxquels participaient des médecins, des patients et des scientifiques, STIM et Mines ParisTech ont mobilisé la méthode C-K afin d’établir une compréhension commune du cancer et du traitement du cancer, ainsi que des données disponibles et des techniques d’analyse des données qui peuvent être utilisées. Cette étape a été cruciale pour construire un vocabulaire commun à tous les experts de différents domaines, contextualiser les approches actuelles à l’aide du cadre C-K et définir les limites des approches actuelles.
Une fois cette compréhension explicitée, il a été plus facile de trouver des solutions de rechange en recherchant les connaissances externes et en cartographiant les produits existants. Pour imaginer ces alternatives, plusieurs ateliers ont été organisés avec des spécialistes de l’analyse des données et du cancer, complétés par une revue de la littérature et un travail de proximité avec l’équipe d’Epidemium. Au total, 25 experts ont participé aux ateliers. Ils ont d’abord partagé leur vision commune du domaine (pour résumer : aujourd’hui, les données sur le cancer sont utilisées par les professionnels de santé, qui les recueillent et les utilisent pour mieux comprendre le cancer ; voir la figure 2 pour l’extrait de la carte).
Des alternatives ont été proposées à chaque niveau de carte. Par exemple : les non-experts peuvent utiliser les données ; différents acteurs peuvent accéder aux données (et pas seulement les professionnels de santé) ; ces données peuvent être utilisées différemment. L’établissement d’une compréhension commune a aidé les experts à identifier des alternatives. Par exemple, aujourd’hui, le dépistage du cancer est principalement effectué par le personnel médical. Les solutions de rechange ont été imaginées pour explorer les techniques d’autosurveillance ou de dépistage réalisées par des tiers (ces techniques de dépistage devraient être non invasives). De plus, le dépistage ne devrait pas se produire seulement lorsque les premiers symptômes apparaissent, mais sur une base régulière. Les personnes à risque devraient être identifiées (par l’analyse du génome, l’âge, le sexe, l’exposition à différents facteurs de risque) et elles devraient bénéficier d’un dépistage individuel fréquent. À l’avenir, on pourra même envisager un dépistage continu en temps réel.
Qu’en est-il des données? Différentes informations étaient pertinentes (en fonction de l’utilisation des données) telles que les données relatives à l’état de santé du patient, à l’efficacité et à la non-efficacité du traitement, au comportement du patient (nutrition, activité, travail), à l’environnement ou à d’autres facteurs externes pouvant affecter une personne; les données épigénomiques, les données relatives aux services de soins aux patients, à l’économie du pays, etc.
Différentes alternatives explorées et structurées grâce au cadre C-K ont permis d’identifier 45 axes d’exploration tels que l’affectation automatique des patients à différents services en fonction d’un type de cancer, la sociologie, les traitements, l’évaluation ex post de l’efficacité ou de l’échec du traitement, mais aussi le risque et l’environnement, l’anticipation de l’efficacité du traitement et des effets secondaires en fonction du profil du patient et, pour chaque organe, la compréhension du type de cancer qui peut survenir.
Les premiers résultats ont été exposés à une communauté épidémique plus vaste (environ 100 personnes) pour recueillir leurs commentaires et suggestions. Les résultats ont été validés avec le comité scientifique et éthique de la communauté Epidemium.
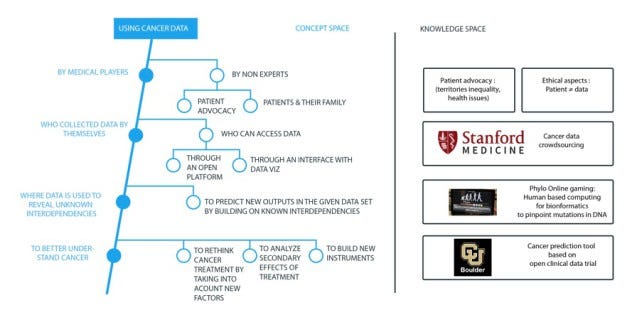
Ce travail de collaboration a aidé la communauté à façonner diverses orientations de recherche et à cerner les connaissances nécessaires pour aller plus loin. La carte est à la disposition de tous ceux qui souhaitent mieux comprendre la problématique du cancer et de son traitement, l’enrichir ou la compléter par des projets existants.
Traiter les nouvelles orientations de la recherche dans un contexte transdisciplinaire
La création d’interdépendances entre des domaines ou des concepts qui n’étaient pas liés auparavant peut mener à des idées inattendues. L’obligation de créer une carte interconnectée de concepts reliés à plusieurs domaines plutôt indépendants a permis à la communauté de l’épidémiologie de créer une proximité entre les différents experts et d’élargir l’espace d’exploration pour créer une compréhension commune.
L’utilisation d’une méthode de conception comme Concept-Knowledge a aidé à comprendre et à explorer diverses solutions de rechange qu’Epidemium peut suivre pour établir des orientations de recherche et voir comment d’autres initiatives sont positionnées, ce qui a donné lieu à une cartographie de la recherche actuelle sur les initiatives d’analyse des données pour le cancer. Cette carte a permis d’explorer et de générer des hypothèses potentielles accessibles à la communauté.
La carte proposée n’est pas exhaustive et elle est sujette à des changements et améliorations constants. Néanmoins, elle offre une vue d’ensemble complète d’un problème complexe et fournit un riche ensemble d’orientations de recherche.
Cette approche visait à explorer systématiquement toutes les alternatives possibles, en essayant ainsi d’éviter les biais cognitifs qui limitent la capacité d’exploration des participants à des solutions trop évidentes ou qui existent déjà. De plus, le traitement des connaissances existantes a favorisé une meilleure compréhension de l’état actuel des connaissances et aidé à organiser la recherche de nouvelles connaissances. Cela a augmenté la capacité des concepteurs à identifier et développer des concepts originaux.
Nous croyons que cette approche offre la possibilité d’élaborer des modèles plus généraux. Il pourrait être intéressant de combiner la stratégie axée sur le design avec des approches de visualisation, de text mining ou de statistiques.
Références
Dorst, K. (2006), “Design problems and design paradoxes,” Design Issues, 22(3), 4–17.
Fecher, B., Friesike, S. & Hebing, M. (2015), “What drives academic data sharing?”, PloS one, 10, e0118053.
Godemann, J. (2008), “Knowledge integration: A key challenge for transdisciplinary cooperation,” Environmental Education Research, 14(6), 625–641.
Gowers, T. & Nielsen, M. (2009), “Massively collaborative mathematics,” Nature, 461, 879–881.
Hatchuel, A., P. Le Masson, Y. Reich and B. Weil (2011), “A systematic approach of design theories using generativeness and robustness,” Proceedings of the 18th International Conference on Engineering Design (ICED11), 2, 87–97.
Felin, T., Zenger, T. (2014), “Closed or open innovation? Problem solving and the governance choice,” Research Policy, 43, 5, 914–925
Hooge, S., M. Agogué and T. Gillier (2012), “A new methodology for advanced engineering design: Lessons from experimenting CK Theory driven tools,” International Design Conference — Design 2012.
Khoury, M. J., Lam, T. K., Ioannidis, J. P., Hartge, P., Spitz, M. R., Buring, J. E., … & Herceg, Z. (2013), “Transforming epidemiology for 21st century medicine and public health,” Cancer Epidemiology and Prevention Biomarkers, cebp-0146.
Le Masson, P., K. Dorst and E. Subrahmanian (2013), “Design theory: history, state of the art and advancements,” Research in Engineering Design 24(2), 97–103.
Sauermann, H. and C. Franzoni (2015), “Crowd science user contribution patterns and their implications,” Proceedings of the National Academy of Sciences, 112(3), 679–684.
Suivez STIM et leurs travaux sur Twitter !

Découvrez puis participez à Epidemium : site et plateforme.
Auteur/Autrice
Collectif inno³