Open Source et IA : trois règlements européens, trois logiques, un même écosystème
Le recours à l’intelligence artificielle (IA) soulève des enjeux juridiques, éthiques et sociétaux majeurs, en Europe auxquels les législateurs tentent de répondre par de nouveaux règlements européens. L’Union européenne s’est dotée du Règlement (UE) 2024/1689 sur l’Intelligence Artificielle (RIA) (ci-après « RIA » ou « AI Act »), qui accorde un régime dérogatoire aux systèmes d’IA Open Source, mais avec des limitations qui révèlent une interprétation étroite de ce qu’est l’« Open Source » en matière d’IA.
Autour de la série de trois articles « Open Source et IA », inno3 propose une analyse du RIA, de son impact sur l’écosystème Open Source aboutissant à des pistes d’actions à implémenter.
- Dans ce premier article « Open Source et IA : les apports du Règlement sur l’Intelligence Artificielle européen« , il s’agit de donner quelques repères clefs sur la place de l’Open Source dans ce Règlement autour des modèles d’IA à usage général (GPAI) et des systèmes d’IA.
- Dans le deuxième article « Open Source et IA : trois règlements européens, trois logiques et un écosystème », l’objectif est de replacer le RIA dans un contexte plus large d’un ensemble de règlements européens (NLPD, CRA, etc.) et d’analyser leurs impacts sur l’écosystème Open Source européen et dans ses dynamiques internationales.
- Dans le dernier article « Open Source et IA : de quoi parle-t-on vraiment ?« , il s’agit d’une part de revenir sur les différentes définitions à l’œuvre sur une IA « open », leurs points de divergence et d’autre part de proposer des pistes d’actions à implémenter.
Ce qu’il faut retenir
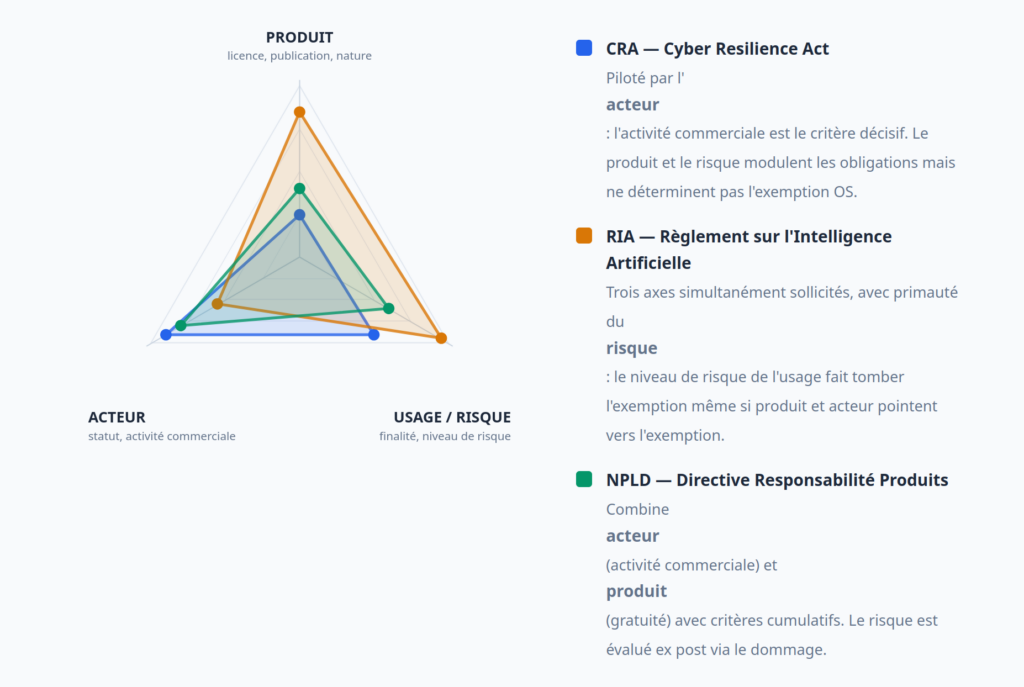
Un développeur ou mainteneur open source fait face simultanément à trois textes européens (CRA, RIA, NPLD) dont les exemptions ne sont pas alignées. Le CRA raisonne en termes d’activité commerciale, le RIA en termes de licence et publication, la NPLD en termes de gratuité. Un même acteur peut être exempté par l’un et soumis par un autre. À l’international, USA, Chine et Europe convergent vers un traitement favorable de l’ouverture, mais pour des raisons radicalement différentes — sécurité nationale (USA), hégémonie numérique (Chine), droits fondamentaux (Europe).
L’écosystème du logiciel libre et de l’Open Source se trouve au cœur d’un faisceau réglementaire convergent : le Règlement sur la résilience cybernétique (CRA, 2024), le Règlement IA (2024), et la Directive sur la responsabilité du fait des produits défectueux (NPLD, 2024), pour ne parler que des normes européennes les plus récentes.
Si l’idée principale de la préservation d’une « innovation ouverte » est claire, chacun de ces textes propose des exemptions pour l’Open Source basées sur des critères différents. Le CRA parle d’« activité commerciale ». Le RIA parle de « licence libre » et de « publication ». La NPLD parle de « fourniture gratuite ». Pour un même mainteneur ou contributeur, les conséquences réglementaires divergent selon le texte considéré.
Ces trois textes partagent un point de convergence fondamental : la régulation de la mise sur le marché, compétence constitutive du droit européen. C’est au moment où un produit (y compris un logiciel, un modèle d’IA) entre dans la circulation commerciale européenne que les obligations se déclenchent. Or, le législateur n’a pas pu simplement exclure l’Open Source de cette logique : l’Open Source n’empêche pas la commercialisation, et il représente une valeur collective considérable. Chaque texte a donc tenté de tracer sa propre ligne entre l’exemption communautaire et l’assujettissement commercial. Le problème est que ces trois lignes ne se superposent pas.
La mise sur le marché : point de convergence des trois règlements européens
L’Union régule la circulation des biens
Le fondement commun des trois textes (CRA, RIA, NPLD) est la compétence de l’Union à règlementer la circulation des biens dans le marché intérieur. Cette compétence repose sur l’article 114 du TFUE (Traité sur le fonctionnement de l’Union européenne), qui autorise le Parlement et le Conseil à adopter des mesures de rapprochement des législations nationales « ayant pour objet l’établissement et le fonctionnement du marché intérieur ». Les trois règlements s’inscrivent dans ce cadre : le CRA et le RIA citent explicitement l’article 114 TFUE comme base juridique ; la NPLD, en tant que directive, s’y appuie également pour harmoniser les régimes de responsabilité. Ce n’est pas anodin : cela signifie que ces textes régulent avant tout la circulation de produits (y compris logiciels et modèles d’IA) dans le marché unique.
La notion pivot est celle de « mise sur le marché » (placing on the market) et de « mise à disposition sur le marché » (making available on the market). Ces concepts ont une longue tradition en droit européen des produits. Ils sont définis de manière harmonisée depuis la Décision n° 768/2008/CE (« Nouveau cadre législatif ») et explicités dans le Guide bleu relatif à la mise en œuvre de la réglementation européenne sur les produits révisé en 2022. Le Guide bleu rappelle que la « mise sur le marché » désigne le premier acte de mise à disposition d’un produit sur le marché de l’Union, et que la « mise à disposition » couvre toute fourniture en vue de la distribution ou de l’utilisation, dans le cadre d’une activité commerciale, qu’elle soit effectuée moyennant paiement ou à titre gratuit. C’est cette formulation (utilisée bien avant l’émergence des textes sur l’IA) que les trois règlements reprennent et adaptent.
Le RIA en donne la déclinaison la plus explicite pour l’IA. L’article 3, point (9), définit « mise sur le marché » comme « la première mise à disposition d’un système d’IA ou d’un modèle d’IA à usage général sur le marché de l’Union ». L’article 3, point (10), précise « mise à disposition sur le marché » : la fourniture d’un système d’IA ou d’un modèle d’IA à usage général en vue de sa distribution ou de son utilisation sur le marché de l’Union, dans le cadre d’une activité commerciale, qu’elle soit effectuée moyennant paiement ou à titre gratuit. Enfin, l’article 3, point (11), définit « mise en service » : la fourniture pour première utilisation directe au déployeur. Le CRA adopte des définitions matériellement identiques (article 3, points 20 à 22), de même que la NPLD dans sa conception du « fabricant » qui « met un produit à disposition ».
Ce qui frappe dans la formulation commune : elle inclut explicitement les fournitures gratuites si elles s’inscrivent dans une activité commerciale. L’Union n’a pas créé une exemption simple pour l’Open Source, elle a plutôt creusé une condition complexe qui rappelle le grand principe selon lequel « Libre ne veut pas dire gratuit ». L’autre apport, qui est source d’anxiété pour beaucoup, est que ces textes visent à offrir une plus grande transparence dans le numérique, pour notamment tracer un produit non conforme jusqu’au fabricant. Cette traçabilité (et responsabilité sous-jacente) met en tension l’écosystème Open Source, où la notion de « fabricant » est fondamentalement distribuée, souvent bénévole et toujours « as is/sans garantie ».
Ainsi, tout le travail du législateur a été, pour chaque texte, de clarifier 1) ce qu’est l’Open Source (les termes utilisés n’étant pas nécessairement les mêmes) et 2) quand l’Open Source bascule de l’exemption à l’assujettissement :
- Le CRA (article 4) exempte les produits développés ou fournis « en dehors d’une activité commerciale ». L’activité commerciale est le curseur : dès qu’elle existe, l’exemption cède. Néanmoins l’articulation avec l’Open Source n’est pas clarifiée et le considérant 18 précise que « le simple fait de publier un logiciel sur un dépôt public ne constitue pas en soi une activité commerciale », ce qui rassure les développeurs bénévoles mais laisse de nombreuses zones grises : sponsoring, rémunération indirecte, intégration dans un service commercial sont-ils décisifs ? Le CRA instaure aussi le statut d’« open-source software steward » (article 3, point 14), une voie intermédiaire pour les fondations qui soutiennent systématiquement les projets libres et qui sont « partenaires » des institutions de régulation.
- Le RIA (articles 2.12 et 53.2) raisonne en termes de licence et publication, non d’activité commerciale. Un système d’IA à haut risque est exclu s’il est fourni « sous une licence libre appropriée » et « avec les composants ou les modèles publié sous une licence libre ». Un modèle GPAI open source bénéficie d’un allègement. Mais le RIA ajoute une condition implicite : le caractère non-monétisé. Le considérant 103 du RIA précise que « les systèmes d’IA [libres] développés sans finalité commerciale [ne sont pas soumis à la plupart des obligations] ». Ainsi, l’exemption repose nominalement sur la forme (licence libre) mais matériellement sur l’absence de monétisation, cette tension entre le dispositif (articles) et l’interprétation (considérants) peut néanmoins se résoudre si on considère une fois encore que le critère principal reste celui de la mise sur le marché.
- La NPLD (considérant 20) combine deux critères : le fournisseur qui met à disposition un logiciel libre « gratuitement et en dehors d’une activité commerciale » n’est pas un fabricant responsable. C’est l’approche qui semble la plus stricte, requérant cumulativement la gratuité ET l’absence d’activité commerciale, mais qui, encore une fois semble pouvoir être harmonisée avec celle des autres textes.
Selon que l’on adopte une vision commune ou non de ces textes, un même mainteneur ou même projet pourrait être exempté par le CRA, assujetti par le RIA, et partiellement couvert par la NPLD — selon les faits.
Les zones grises : entre exemption formelle et réalité marchande
Plusieurs configurations demeurent indécises, certaines ayant déjà été discutées dans le cadre de l’analyse du CRA :
- Le mainteneur salarié d’une grande tech : un développeur Google, Meta ou Microsoft, payé 150 k€ par an, consacre 20 % de son temps à maintenir un projet Linux ou PyTorch. Son employeur en tire du prestige, de l’influence technique, de la séduction talentueuse. Y a-t-il « activité commerciale » ?
- La fondation qui reçoit des dons ou du sponsoring : certaines fondations Open Source reçoivent des dons et des cotisations qui se comptent en million pour maintenir certains logiciels directement ou indirectement important pour l’activité commerciale de celui qui finance. Y a-t-il « activité commerciale » ? ça se discute d’autant plus lorsqu’on explore les différents types de statuts susceptibles d’être utilisés par ses fondations, qui certaines sont très proches de société (qui mutualiseraient les développements pour leur membre).
- Le modèle open core ou freemium : une startup propose une version open source de sa plateforme + une version enterprise payante (features additionnelles, support, infrastructure). Qui est soumis au CRA, au RIA, à la NPLD ? La version open source isolée, techniquement, relève de l’exemption : gratuit, licence libre, pas de monétisation directe de ce composant. Les guidelines relatives au CRA considère qu’il faut appliquer « situations contractuelles par situations contractuelles », ce qui pourrait poser des difficultés au regard des pratiques autour des licences Open Source (qui ne sont que des offres de contracter, c’est-à-dire que le formera lorsque les personnes accepteront la licence, sans nécessairement que l’on en soit informé).
- Le dual-licensing un éditeur propose une version GPL du code et une licence propriétaire payante. Même question : l’exemption couvre-t-elle la version GPL isolée ?
Ce que l’on pressent du législateur, c’est qu’il entend assujettir tous les opérateurs économiques aux mêmes règles (qu’ils soient ou non contributeurs aux logiciels libres et Open Source), ce qui présente l’avantage d’un traitement égal, mais qui pose la question de l’équité : est ce normal que des entreprises qui contribuent massivement à l’infrastructure numérique ouverte européenne soient soumises aux mêmes règles que les géants du numérique qui réutilisent leur logiciel ? La réponse est certainement du domaine de la sanction, mais mérite d’être formulée car la résilience à l’action judiciaire n’est pas la même pour tous.
À cela s’ajoute les autres acteurs qui participent au déploiement des logiciels Open Source (en contribuant ou non), car même si un composant Open Source peut être exempté dans un contexte, il ne le sera pas dans un autre qui redeviendrait commercial. Ainsi, le considérant 19 du CRA le précise : « Les producteurs qui incorporent ou modifient des produits FOSS dans leurs propres produits doivent se conformer aux exigences du présent règlement ». Cela crée une fragmentation de responsabilité, internalisant potentiellement le coût de la conformité chez ceux qui commercialisent.
Il y a donc plusieurs urgences :
- Clarifier ce qui est entendu par logiciel libre et/ou Open Source et par le concept de mise sur le marché. Les textes existent, malheureusement l’implémentation dans ces trois textes législatifs démontrent un besoin d’harmonisation ;
- Faire en sorte que cette complexité réglementaire soit accompagnée aussi d’un dispositif de protection de l’écosystème Open Source bénévole, qui ne pourra que très douloureusement se défendre devant les tribunaux en cas d’action (notamment pour la NDLD) ;
- Réfléchir à un élargissement du concept d’« open-source software steward » au-delà du CRA.
La dimension internationale et les couches réglementaires additionnelles
Sans surprise, l’Europe n’est pas la seule à réguler les IA — y compris les IA Open Source. Le sujet est ainsi traité :
- aux États-Unis (sécurité nationale) : ouvrir les modèles qui ne sont pas techniquement sensibles pour accélérer l’innovation et maintenir la supériorité compétitive.
- en Chine (hégémonie numérique) : publier largement pour devenir la base technologique incontournable du monde.
- en Europe (droits fondamentaux) : réglementer l’IA ouverte et fermée pour protéger les citoyens, même au risque de ralentir l’innovation.
Ces trois logiques sont cohérentes avec leurs contextes géopolitiques respectifs, mais ne sont pas conçues pour s’articuler.
L’export control aux États-Unis : l’EAR AI Diffusion Framework
En janvier 2025, le Bureau of Industry and Security (BIS) du Département du Commerce américain a adopté un AI Diffusion Framework (ADF) qui encadre l’exportation des poids de modèles d’IA.
Le régime comporte un seuil technique : les modèles avec plus de 10^26 FLOP (unités de calcul) sont soumis à un contrôle d’exportation. Mais l’exemption clé : les poids rendus publics (Open Source) échappent au contrôle. C’est une approche inverse de l’Europe : au lieu de réglementer l’ouverture, les États-Unis l’incitent en l’exemptant des contrôles d’export.
La logique est clairement géopolitique (sécurité nationale) et résulte aussi du mécanisme extraterritorial sous-jacent (il est nécessaire de laisser des libertés pour pouvoir ensuite sanctionner avec force ce qui se passe outre atlantique). L’EAR vise à empêcher les transferts de technologie vers les adversaires (Chine, Iran, Russie). Mais l’ouverture (publication globale) est une fuite inévitable. L’implication est qu’un mainteneur européen contribuant à un projet ML collaboratif avec des acteurs US doit vérifier que le projet n’est pas soumis à l’EAR, sachant qu’un modèle américain Open Source soumis à l’EAR mais publié globalement échappe au contrôle (mais demeure soumis au RIA en Europe).
Cette entrée des Modèles dans le périmètre de l’EAR (pour les biens à double usage) semble pouvoir être rapprochées des actualités récentes qui ont opposé les grandes plateformes d’IA au Ministère de la Guerre américain.
Le règlement européen sur les biens à double usage (UE 2021/821) s’applique également aux technologies d’IA dont les composants cryptographiques relèvent des catégories contrôlées. Cette triple couche (EAR américain, RIA européen, dual-use européen) constitue un enchevêtrement qui pourra faire l’objet d’un article dédié dans cette série.
Chine : la stratégie d’hégémonie numérique
En 2023, la Chine a adopté des Mesures provisoires pour la gestion des services d’IA générative qui prévoient une exemption R&D et usage interne. Depuis, la Chine a amplifiée une stratégie d’ouverture massive de modèles : DeepSeek, Qwen (Alibaba), et d’autres ont accumulé plus de 700 millions de téléchargements cumulés en 2025-2026.
C’est une stratégie consciente de « dominer par l’ouverture ». Les modèles chinois, publiés librement, deviennent l’infrastructure mentale de l’écosystème mondial. Les développeurs, les startups, les académiques du monde entier entraînent et peaufinent des modèles chinois. C’est une forme de soft power, qui crée une dépendance technologique à terme. De fait, un modèle GPAI chinois publié sous licence ouverte est soumis au RIA (au moins au niveau de l’intégrateur), ce qui peut être d’autant plus complexe compte tenu des obligations « politiques » auxquelles doivent se conformer les entrerprises chinoises (y compris en termes de création de modèle).
En Europe : droit d’auteur, TDM et données d’entraînement – un angle mort réglementaire
L’entraînement des modèles d’IA (y compris des modèles open source) repose massivement sur le Text and Data Mining (TDM) de contenus protégés par le droit d’auteur. La directive (UE) 2019/790 sur le droit d’auteur dans le marché unique numérique prévoit deux exceptions TDM : l’article 3 (exception de recherche scientifique, sans opt-out possible) et l’article 4 (exception commerciale, soumise au droit d’opt-out des titulaires). Le RIA, dans ses articles 53(1)(c) et (d), impose à tout fournisseur de modèle GPAI (y compris open source) de mettre en œuvre une politique de respect du droit d’auteur et de publier un résumé des données d’entraînement utilisées. C’est l’une des rares obligations maintenues même pour les modèles GPAI bénéficiant de l’allègement de l’article 53(2).
Cette intersection entre droit d’auteur et régulation de l’IA crée des tensions spécifiques pour l’écosystème ouvert. Un modèle Open Source entraîné sur des données dont l’opt-out n’a pas été vérifié s’expose à un risque contentieux au titre de la directive droit d’auteur et à un défaut de conformité au titre du RIA. La question se complique lorsque les données d’entraînement sont elles-mêmes issues de datasets ouverts (Common Crawl, LAION) dont la licéité TDM est disputée. Ces questions, qui mêlent droit d’auteur, droit des données et régulation sectorielle, méritent un traitement approfondi qui pourra aussi faire l’objet d’un article ultérieur dans cette série.
Conclusions
L’Open Source comme terrain d’innovation : une doctrine à affirmer
Face à cette complexité réglementaire, il convient de rappeler que l’open source n’est pas seulement un objet juridique à réguler, mais aussi un terrain d’innovation à protéger. Le Manifeste Open Source publié en 2025 par Numeum articule une vision claire : l’Open Source est un levier de compétitivité, de souveraineté et d’innovation pour l’Europe, et non un simple mode de distribution de logiciels.
Le Manifeste identifie quatre priorités : intégrer l’open source dans toutes les transitions technologiques clés (IA, cloud, cybersécurité), l’inscrire dans les standards et régulations européennes pour garantir transparence et interopérabilité, soutenir les communautés de développement, et en faire un composant par défaut des marchés publics. Cette doctrine rejoint les travaux de la Commission européenne qui, dans sa stratégie « European Open Digital Ecosystems » en consultation en 2025-2026, envisage l’open source comme un actif stratégique au service de l’autonomie numérique de l’Union.
L’enjeu est que la régulation ne contredise pas la politique industrielle. Si l’Europe affirme d’un côté que l’open source est un pilier de sa souveraineté numérique (comme le suggère le rapport Draghi et les initiatives de la DINUM) elle ne peut pas, de l’autre, imposer un cadre réglementaire qui fragilise les acteurs mêmes qui constituent cet écosystème. Le CRA, le RIA et la NPLD doivent donc être lus non seulement comme des textes de conformité, mais aussi à l’aune de cette ambition industrielle et politique.
En harmonisant les obligations pour tous les acteurs commerciaux sans distinguer la nature de leur contribution, on risque de fragiliser le terreau même que l’on dit vouloir encourager. Si contribuer à un projet open source expose une entreprise aux mêmes obligations que développer un produit propriétaire, l’incitation économique à contribuer aux communs s’affaiblit. Les entreprises pourraient rationnellement préférer consommer de l’open source (en tant qu’intégrateurs) plutôt que d’y contribuer (en tant que mainteneurs ou co-développeurs), puisque la contribution active accroît leur surface de conformité sans bénéfice réglementaire. Ce serait un résultat directement contraire à l’ambition affichée par la Commission européenne dans sa stratégie sur les écosystèmes numériques ouverts.
Un besoin de clarification
Les trois règlements européens convergent sur un même point d’ancrage : la mise sur le marché comme moment déclencheur des obligations. Mais le législateur, confronté à un objet (le logiciel open source) qui circule librement, massivement et souvent gratuitement tout en produisant une valeur économique considérable, n’a pas pu tracer une ligne unique. Chaque texte a forgé son propre critère : l’activité commerciale (CRA), la licence et l’ouverture (RIA), la gratuité cumulée à l’absence d’activité commerciale (NPLD). Ces trois approches se chevauchent sans se recouvrir.
Si l’Europe ne pouvait ni ignorer l’Open Source (trop de valeur), ni l’exempter totalement (trop de risques), ni le traiter exactement comme le logiciel propriétaire (trop de dommage collatéral), trois chantiers semblent s’imposer :
- Une clarification administrative : le Bureau de l’IA et les autorités nationales doivent publier des lignes directrices consolidées qui harmonisent l’interprétation de l’« activité commerciale » entre les trois textes.
- L’innovation institutionnelle : étendre le concept de steward au-delà du CRA, créer un passeport de conformité transversal, et surtout reconnaître le rôle spécifique des entreprises-contributrices aux communs numériques comme distinct de celui des éditeurs commerciaux.
- L’ambition doctrinale : l’Europe doit affirmer une doctrine explicite et cohérente où la régulation de l’IA et la promotion de l’open source comme bien commun ne se contredisent pas.







